任務定義
Emoji 序列與繁體中文的雙向翻譯——不是字典查找,而是理解 Emoji 在台灣網路文化中如何承載意義的情境理解。
資料集
從頭打造:透過群眾外包收集 emoji 對應中文的映射,再進行規則增強。核心挑戰:emoji 意義高度依賴情境,因平台、年齡層和台灣特有的網路用語而異。用三種不同的演算法/GPT 生成資料比例(20/80、50/50、80/20)評估資料組成的影響。
模型與結果

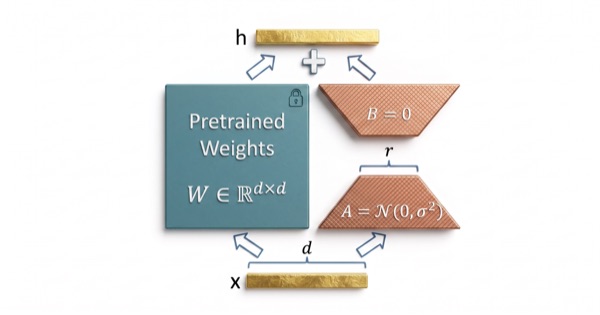
使用 LoRA 搭配 RLHF 風格的偏好優化對 Taiwan-LLaMA 和 Google mT5 進行微調。
mT5 表現優於 LLaMA,原因是其針對繁體中文的明確多語言預訓練。
最有趣的發現:BLEU 分數高的模型在「聽起來自然」的人工評估上表現明顯更差——評估指標偏離目標的典型案例。我們加入 METEOR 評估和多輪人工標注來抓出這個落差。